AI Brain Surgery on a Small Model: Can One SAE Feature Control Behavior?
I wanted to test a concrete question:
Can I take one SAE feature, turn its gain up/down like a knob, and get measurable behavior control?
Short answer: partially yes—with caveats.
TL;DR (Layman Version)
Think of the AI like a brain with tiny dials for different behaviors. I found one dial that we can reliably turn, and when I turned it all the way down, the AI’s output shifted in a measurable way. The effect is real but not huge yet, so this is early-stage brain surgery, not full mind control.
I got reliable latent control and at least one measurable behavior effect under stronger evaluation conditions, but the curve is still noisy.
Why This Matters
It is easy to produce feature galleries. It is harder to show causal control.
For this to be useful, we need four things:
- feature ranking that picks plausible intervention targets,
- a non-confounded intervention method,
- behavior metrics with enough power,
- honest reporting when effects are small.
That is the practical “AI brain surgery” frame: 1) find a circuit, 2) turn it, 3) check symptoms.
Setup (Condensed)
- Model:
EleutherAI/pythia-70m-deduped - Layer/stream: layer 3, MLP output
- Data: wiki-focused (
wikitext-2-raw-v1for target analysis) - Hardware: local Apple Silicon (MPS)
Phase A: Initial SAE (dense)
My initial SAE (ReLU + L1) reconstructed very well but was dense:
- Train A → Eval A: MSE
0.00124, R²0.991 - Avg L0 around
620/768
That was a red flag for behavior control: dense features are usually entangled.
Phase B: Sparse retrain (top-k)
I retrained with hard sparsity:
d_sae=2048topk=32epochs=40
Results (A-trained checkpoint):
- Train A → Eval A: MSE
0.02258, R²0.838, Avg L032
So reconstruction degraded a lot (expected), but sparsity became explicit and controllable.
Note: this run intentionally prioritized intervention quality over pure reconstruction fidelity.
What Changed and Why
Early behavior experiments were weak for two methodological reasons:
- Intervention confound: replacing activations with
decode(encode(x))introduced a global reconstruction offset. - Weak measurement: one-step token checks and tiny prompt sets were underpowered.
I fixed both:
- Residualized intervention:
h0 = encode(x)h1 = h0with one feature scaled byalphax' = x + (decode(h1) - decode(h0))
This makes alpha=1 a true no-op for feature scaling.
- Stronger evaluation:
- activation-gated edits (intervene mostly where the feature is active),
- minimal-pair prompts (sports-like vs non-sports controls),
- rollout logprob mass over multiple steps,
- bootstrap confidence intervals.
Core Results
1. Feature Ranking Found Plausible Targets
In the sparse run, top candidates included theme-like features (sports/music/literature/etc.).
A locked sports-leaning candidate was feature 64. In practice, it tends to activate on sports-structure language like team, season, game, playoffs, and coach style contexts.
2. Latent Knob Control Was Reliable
Across anchored probes, decreasing alpha consistently reduced the target feature’s latent activation.
This is the strongest mechanistic result in the run: the knob is a real control handle.
3. Behavioral Signal: Small but Measurable for One Feature
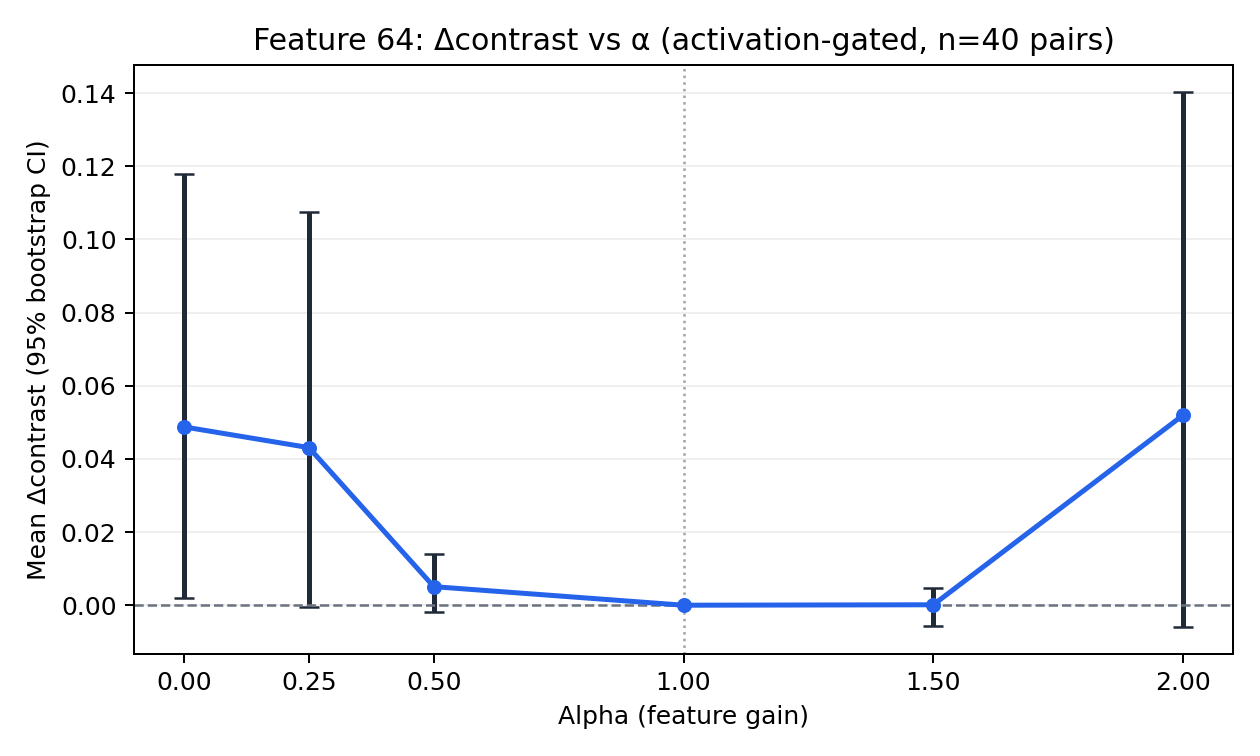
With feature 64, activation-gated residual intervention, and 40 minimal pairs:
- alpha = 0.00: mean
Δcontrast = +0.048736 - Bootstrap 95% CI:
[+0.002094, +0.117822]
Here, Δcontrast is the change in target-vs-control completion score (sports-target logprob mass on the sports prompt minus its matched control prompt), so a positive value means the intervention increased separation between the paired completions.
This clears zero for that condition.
A quick qualitative example (same prompt, same sampling seed):
Prompt: “In the final game, the player scored in overtime and won the …”
alpha = 1.0 (baseline): “…the game for a total of three. … the one by Maui and Maui …”
alpha = 0.0 (feature 64 suppressed): “…the game for a total of three. … the one by Mendoza and Mendoza …”
This is not a dramatic rewrite, but it is a concrete text-level shift under intervention, which is the point of the experiment.
Caveat:
- variance remains large,
- curve is not cleanly monotonic across all alpha values,
- effect size is modest.
So this is a measurable effect, not a solved steering pipeline.
Interpretation
What I think this means:
- Mechanistic control is easier than robust behavior control in this small setup.
- Sparse training regime mattered more than just “more epochs” alone.
- Evaluation design mattered as much as training objective.
In practice, this was less “flip one neuron and magic happens” and more “careful surgery + careful diagnostics.”
Limitations
- Single small model (70M), single layer/stream.
- Custom prompt probes, not broad benchmark suites.
- Moderate variance at strong interventions.
- No claim of universal or monotonic behavior control.
Next Steps
- Increase minimal pairs (40 → 100+) and stratify by template family.
- Add matched random-feature controls with identical gated protocol.
- Evaluate neighboring top features in this same sparse regime.
- Try intermediate sparsity (
topk=64) to recover fidelity while preserving steerability.
References
- Bricken et al. (2023), Towards Monosemanticity: Decomposing Language Models With Dictionary Learning.
- https://transformer-circuits.pub/2023/monosemantic-features/index.html
- https://www.anthropic.com/news/towards-monosemanticity-decomposing-language-models-with-dictionary-learning
- Gao et al. (2024), Scaling and Evaluating Sparse Autoencoders (arXiv:2406.04093).
- https://arxiv.org/abs/2406.04093