May 18, 2026
9 min read
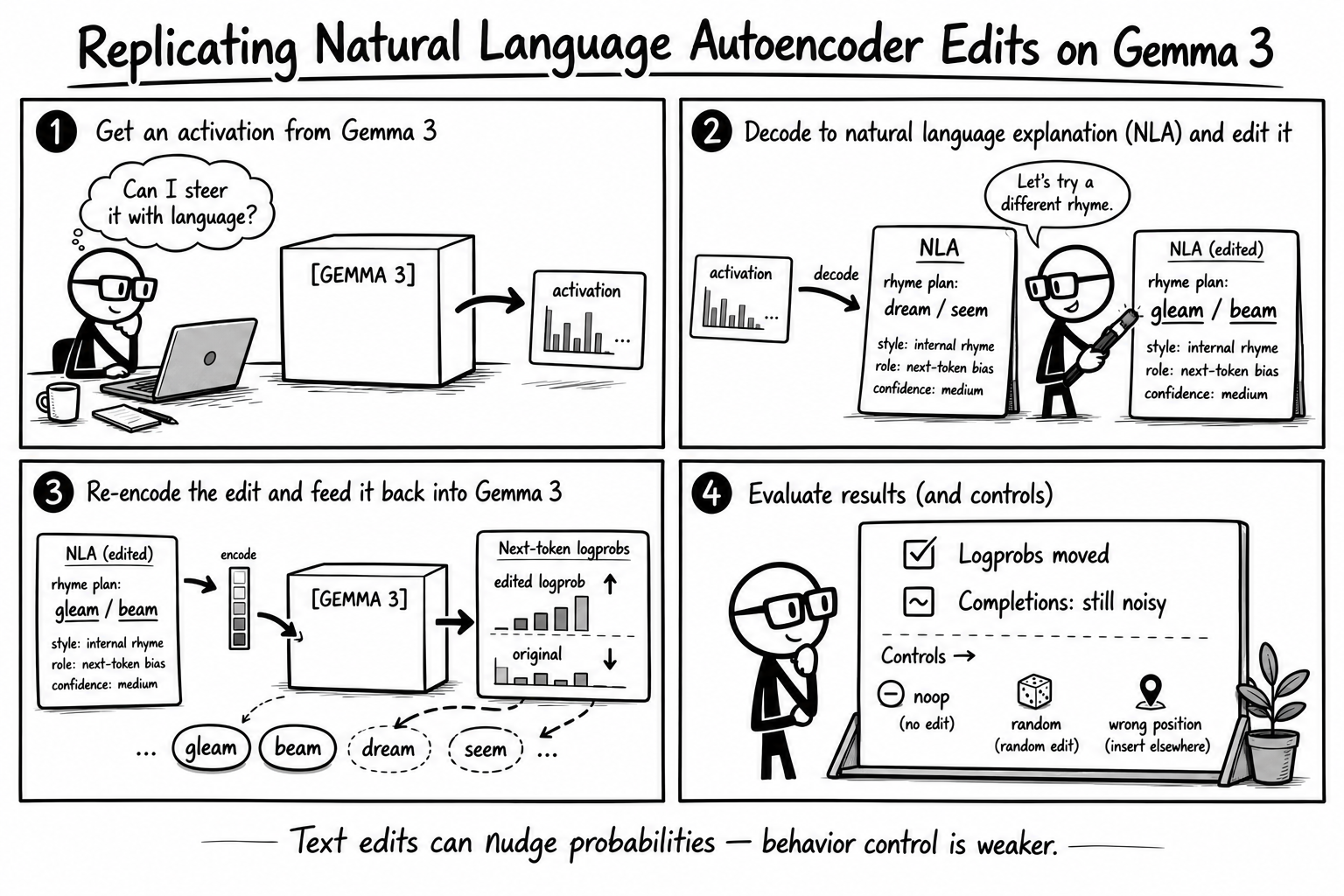
Replicating Natural Language Autoencoder Edits on Gemma 3
A local inference-side replication of Natural Language Autoencoder explanation and edit probes on Gemma 3 12B. The logprob evidence moved in the intended direction; behavioral steering was still weak.
Read featured post
→
ai
interpretability
mechanistic-interpretability
gemma
autoencoders
Latest field note from the lab archive.
March 29, 2026
8 min read
Did My Tiny Transformer Learn an Internal FSM State?
I trained a tiny decoder-only transformer from scratch on a finite-state-machine task, then probed its activations. The strongest evidence was a fragile mid-training next-state representation, not a robust learned state machine.
ai
interpretability
transformers
mechanistic-interpretability
Read post
→
March 3, 2026
11 min read
Hardening SAE Steering on Gemma: Only Code Survives the Controls
I ran a hardened Gemma SAE steering evaluation with holdout prompts, matched controls, wrong-hook checks, and seed extensions. Code held up; most other categories did not.
ai
interpretability
sparse-autoencoders
mechanistic-interpretability
Read post
→
March 1, 2026
10 min read
AI Brain Surgery on a Small Model: Can One SAE Feature Control Behavior?
A wiki-only SAE intervention lab on Pythia-70M: feature ranking, residualized feature knobs, and activation-gated minimal-pair behavior tests.
ai
interpretability
sparse-autoencoders
transformers
Read post
→
February 24, 2026
9 min read
From Tokens to Concepts: Building a Local SAE Interpretability Lab on an M1 Mac
Layer sweeps, top-k sparsity sweeps, and an interactive explorer for SAE feature discovery on a small open-weight model.
ai
interpretability
transformers
sparse-autoencoders
Read post
→
February 22, 2026
8 min read
Interpretability via Sparse Autoencoders on a Small Open-Weight Transformer
A local-only SAE feature probing experiment on Pythia-70M: activation extraction, sparse autoencoder training, cross-domain generalization, and blog-ready artifacts.
ai
interpretability
transformers
pytorch
Read post
→
September 29, 2025
6 min read
Building a Name CLI with GPT-5-Codex
Pairing with GPT-5-Codex to turn the SSA baby-name dataset into a polished Go CLI with weighted sampling, charts, and automated releases.
ai
go
cli
Read post
→