Research Note
Did My Tiny Transformer Learn an Internal FSM State?
I wanted to answer one practical question:
If I train a tiny transformer from scratch on a synthetic finite-state-machine task, does it actually learn an internal state, or does it just learn to guess the final answer token?
Short answer: weakly and transiently, but not convincingly. The strongest internal signal showed up in a smoke run at a mid-training checkpoint, not in the larger multi-seed evaluation. I did not find evidence that the final model had learned a robust, generalizing FSM solver.
TL;DR (Layman Version)
I trained a very small AI model to keep track of a simple state machine. On one small smoke test, it looked surprisingly good. On a larger and more careful multi-seed evaluation, that result mostly disappeared. The strongest thing I found was a temporary internal “next state” signal in the smoke run, not convincing evidence that the final model had really learned the whole state machine.
Why This Post Exists
This experiment produced one reassuring result and one uncomfortable one.
The reassuring result was a smoke run that looked strong on longer traces. The uncomfortable result was that a larger three-seed evaluation pushed long-horizon accuracy back to roughly chance. That made the real question narrower: even if the final answer metric was weak, did any transient state-tracking signal appear inside the model during training?
Checkpointed probing was the only reasonable next step. It let me inspect intermediate models instead of pretending the final accuracy number was the whole story.
What Changed And Why
My earlier goal was to get a “pretty decent” FSM model. That did not really happen.
I added a scratch-training path to the lab, trained a small decoder-only transformer on a synthetic finite-state-machine task, and tried a few tuning passes. The smoke run made it look like I had something. The broader evaluation said I mostly did not.
So this post is not a victory post about solving the task. It is a narrower write-up about what, if anything, the checkpoints reveal internally once the headline accuracy result stops holding up.
Setup
- Model: local tiny decoder-only transformer
- Architecture:
d_model=96,n_layers=4,n_heads=4,d_ff=384,max_seq_len=48 - Task: hidden-state trace completion on one deterministic finite-state machine
- States / symbols: 8 states, 4-symbol alphabet
- Train lengths: traces of length 4 to 6
- Long-horizon probe lengths: traces of length 7 to 10
- Objective: answer-only loss plus auxiliary next-state supervision (
state_aux_weight=1.0) - Smoke training schedule: 10 epochs, batch size 32, learning rate
5e-4 - Probe method: multinomial linear probes trained on checkpoint activations from
seen_evaland evaluated onunseen_eval
The task format is simple: the model sees a start state and a sequence of input symbols, but not the intermediate hidden states. It has to predict the final state.
The probing protocol is also simple on purpose. For each checkpoint and layer, I extracted activations at each symbol position and trained a linear classifier to predict either:
- the current FSM state, or
- the next FSM state
That follows the basic probe idea from Alain and Bengio: if a variable is linearly decodable from a representation, that tells you something about what information is present there, even if it does not prove the full computation is being implemented there.
Core Results
The first thing I had to disentangle was the smoke-run story from the broader evaluation story.
Smoke Run: Looks Good
On the original smoke config, the model went from 0/128 correct on the long-trace eval at initialization to 75/128 correct by the halfway checkpoint, and it stayed there at the final checkpoint.
The by-length buckets in that smoke run were also small enough to be easy to overread:
- length 7:
17/34 - length 8:
20/32 - length 9:
17/34 - length 10:
21/28
That was enough to look exciting, but not enough to trust on its own.
Larger Eval: Mostly Falls Apart
That story did not survive a better check.
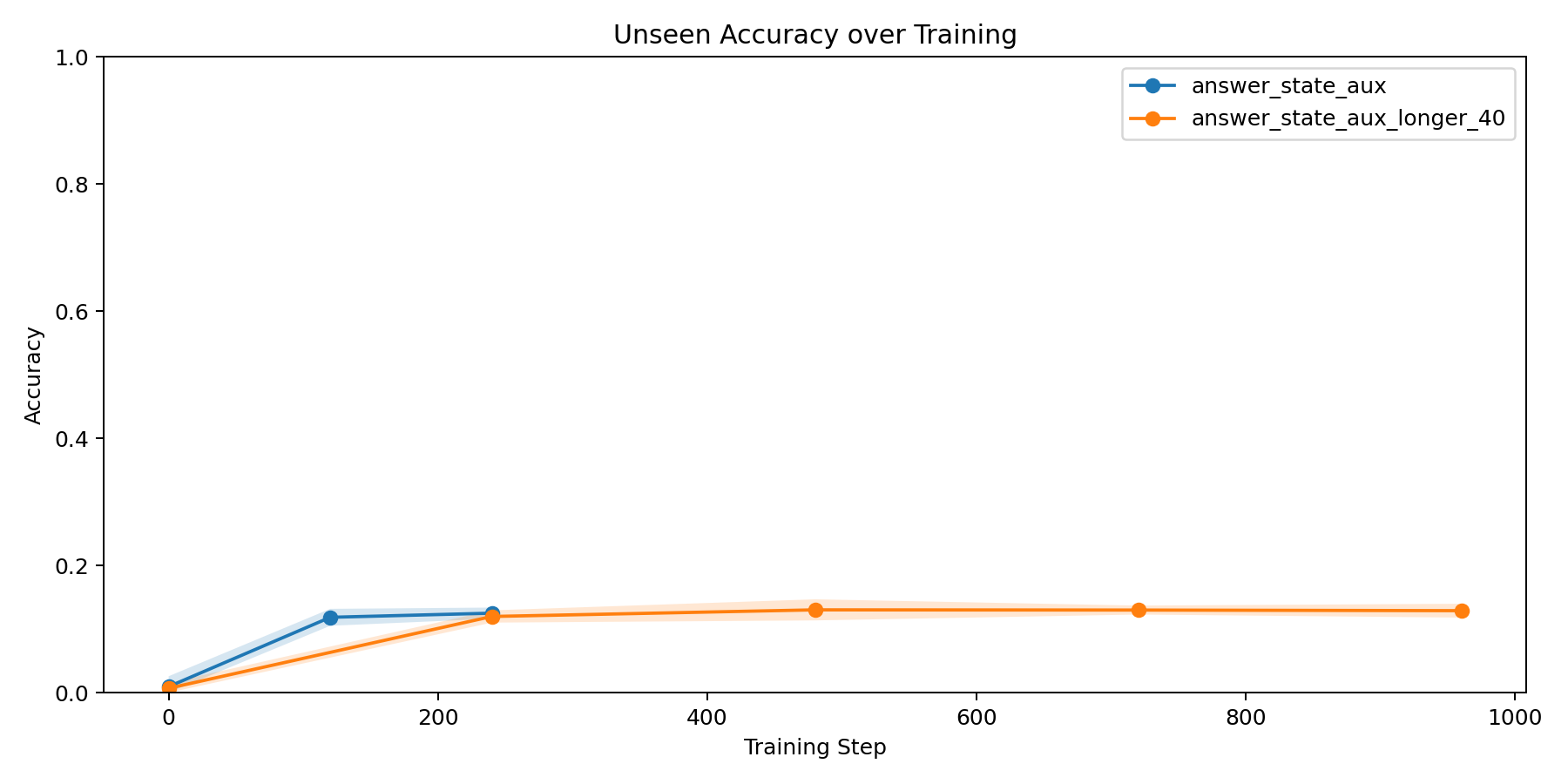
I reran the experiment with a larger long-trace validation setup and aggregated across 3 seeds. With 8 states, uniform chance is 1/8 = 0.125.
For the baseline scratch recipe (answer_state_aux):
- final
unseen_evalmean:0.1250 +/- 0.0088 - selected checkpoint
unseen_evalmean:0.1185 +/- 0.0133
For a longer-training variant (answer_state_aux_longer_40):
- final
unseen_evalmean:0.1289 +/- 0.0109 - selected checkpoint
unseen_evalmean:0.1234 +/- 0.0078
That is the number that reset my confidence. Training longer did not rescue long-horizon generalization in any meaningful way.
So the answer metric said: the final model is not a robust FSM solver.
What The Probe Found
Even with the answer metric looking weak, the probe results were still worth checking.
Current State Is Decodable, But Not Persuasive
current_state was already fairly decodable at initialization, which makes it a weak signal for “learned latent state.”
For example, on late unseen steps:
- layer 0
current_stateaccuracy atbase:0.375 - layer 0
current_stateaccuracy atfrac_050:0.138 - layer 0
current_stateaccuracy atfrac_100:0.202
The majority baseline there was only 0.167, so the representation is carrying real information. But because the untrained model already exposes a lot of it, and training mostly makes it worse, I do not think this is the right place to make a strong claim.
Next State Is More Interesting
next_state is where the best evidence shows up.
On late unseen steps, the layer-0 probe moved like this:
base:0.381frac_050:0.526frac_100:0.484
At layer 3:
base:0.282frac_050:0.452frac_100:0.372
The important caveat is that the majority baseline for this target is high: 0.427. So not all of that apparent performance is impressive. The clearest improvement is at layer 0, where the halfway checkpoint reaches 0.526. At layer 3, the halfway checkpoint only gets to 0.452, which is positive but not by much.
That is the narrow claim I am willing to make from this smoke run:
mid-training, the model appears to form a more linearly decodable representation of the next transition state, especially on steps beyond the training horizon.
I am not willing to stretch that into “the model learned an internal FSM” without stronger evidence.
Visuals And Artifacts
The two most useful plots are:
- the long-trace answer metric over training, which shows how weak and unstable the larger-eval result really is,
- and the late-step probe plot, which shows the temporary improvement in
next_statedecodability around the middle checkpoint.
The tagged lab snapshot for this write-up is here:
exp-2026-03-28-fsm-state-probe- github.com/curtiscovington/sae-interpretability/tree/exp-2026-03-28-fsm-state-probe
Interpretation
My current read is:
- the smoke task was easy to overread,
- the larger long-trace evaluation says the model is not robustly solving the FSM problem,
- and the best internal signal I found is a temporary increase in next-state decodability at a smoke-run checkpoint, not a stable mechanistic result.
The narrow conclusion is that, in this smoke-run setup, training may briefly pass through a regime where next-state information is more linearly recoverable from the hidden states, then fail to stabilize that into reliable long-horizon behavior. That is weaker than showing a stable internal FSM, and much weaker than the mechanistic evidence in the papers I cite below.
Limitations
- The strongest probe result came from a smoke run, not the larger multi-seed eval harness.
- Linear probes measure decodability, not necessarily the causal computation the model is using.
current_statebeing decodable at initialization means raw decodability alone is not enough evidence here.- The
next_statetarget has a relatively strong majority baseline, so apparent gains need to be interpreted conservatively. - I only tested one tiny architecture family and one synthetic FSM setup.
Next Steps
If I want a genuinely decent FSM model, I think the next useful steps are:
- add a stronger inductive bias for state tracking instead of just training longer,
- run the latent-state probe across larger-eval checkpoints and more seeds,
- test whether the probe-positive checkpoint is causally special, not just more linearly readable,
- and separate “representation briefly appears” from “representation supports stable long-horizon generalization.”
That last distinction matters. Right now I have better evidence for the first than the second.
References
- Guillaume Alain and Yoshua Bengio (2016), Understanding intermediate layers using linear classifier probes.
- Gail Weiss, Yoav Goldberg, and Eran Yahav (2021), Thinking Like Transformers.
- Yifan Zhang, Wenyu Du, Dongming Jin, Jie Fu, and Zhi Jin (2025), Finite State Automata Inside Transformers with Chain-of-Thought: A Mechanistic Study on State Tracking.