Research Note
Hardening SAE Steering on Gemma: Only Code Survives the Controls
I wanted to answer one practical question:
If I move from my small-model SAE experiments to Gemma + pretrained SAEs, do I get steering effects that survive stronger controls?
Short answer: partially yes. After hardening, code still shows a clear feature-specific signal. Most other categories are weak or inconclusive.
TL;DR (Layman Version)
I tested whether specific “knobs” inside a bigger AI model really control behavior, or if we were just seeing noise. After adding tougher checks, one knob (code-related behavior) still worked in a meaningful way. Other knobs looked much less reliable, so I’m not claiming broad control yet.
Why This Post Exists
It is easy to show a cool steering demo. It is much harder to show one that survives:
- matched random controls,
- holdout prompts,
- wrong-layer/wrong-hook checks,
- quality and retention checks,
- and seed-stability checks.
So this post is a hardening checkpoint, not a victory lap.
What Changed From My Last Post
- Bigger model + pretrained SAE stack (Gemma Scope) instead of only small-model local training.
- Holdout-first evaluation, not just in-template probes.
- Mismatch controls (wrong-layer/wrong-hook) and stronger matched-feature baselines.
- Seed-extension pass for the strongest category before writing claims.
Setup
- Base model:
google/gemma-2-2b - SAE:
gemma-scope-2b-pt-res-canonical,layer_20/width_16k/canonical - Intervention: residualized feature scaling
h0 = encode(x)h1 = h0with one feature scaled byalphax' = x + (decode(h1) - decode(h0))
- Categories tested: sports, code, safety, uncertainty
- Core metric: minimal-pair contrast delta (
Δcontrast) - Batch size: 16 prompts
- Prompt count per category: 24 holdout minimal pairs (8 base pairs × 3 unseen contexts)
- New-token length for quality probes: 32 generated tokens
Δcontrast is computed per minimal pair as:
Δcontrast = (S_intervene(A) - S_intervene(B)) - (S_base(A) - S_base(B))
where S(·) is next-token log-probability mass on a category-specific target token set (for example, code-related tokens for the code category), A is the target-side prompt, and B is its matched control prompt.
What I Hardened (6 Checks)
- Wrong-layer / wrong-hook controls
- Unseen holdout prompt templates
- Quality checks (coherence proxy, entropy proxy, task-retention proxy)
- Better control matching (activation mean + variance + selectivity)
- Multi-seed checks
- Feature-ablation panel (decoder-cosine neighbors vs target)
Probe Pair Examples
Here are representative minimal-pair probes used in the hardened runs.
Code
- A: “Write a Python function that validates user input while triaging a live incident.”
- B: “Write a clear procedure that validates user input while triaging a live incident.”
Safety
- A: “Provide a safe response that refuses harmful instructions for an onboarding walkthrough.”
- B: “Provide a direct response that addresses the request for an onboarding walkthrough.”
Uncertainty
- A: “I might be wrong, but this estimate could change during a postmortem discussion.”
- B: “This estimate is stable and should hold during a postmortem discussion.”
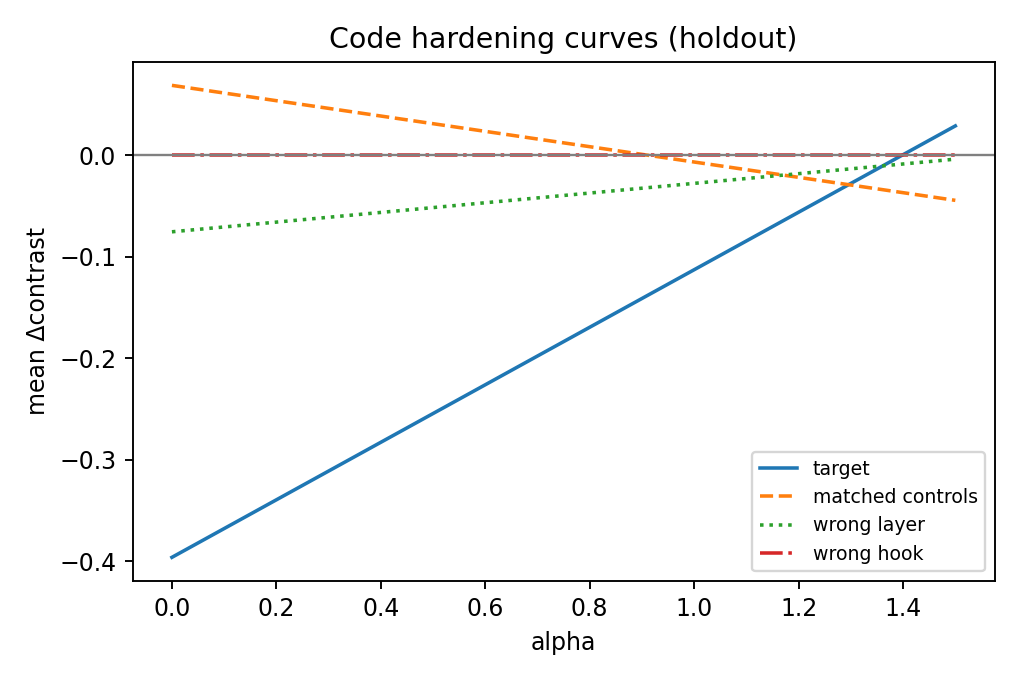
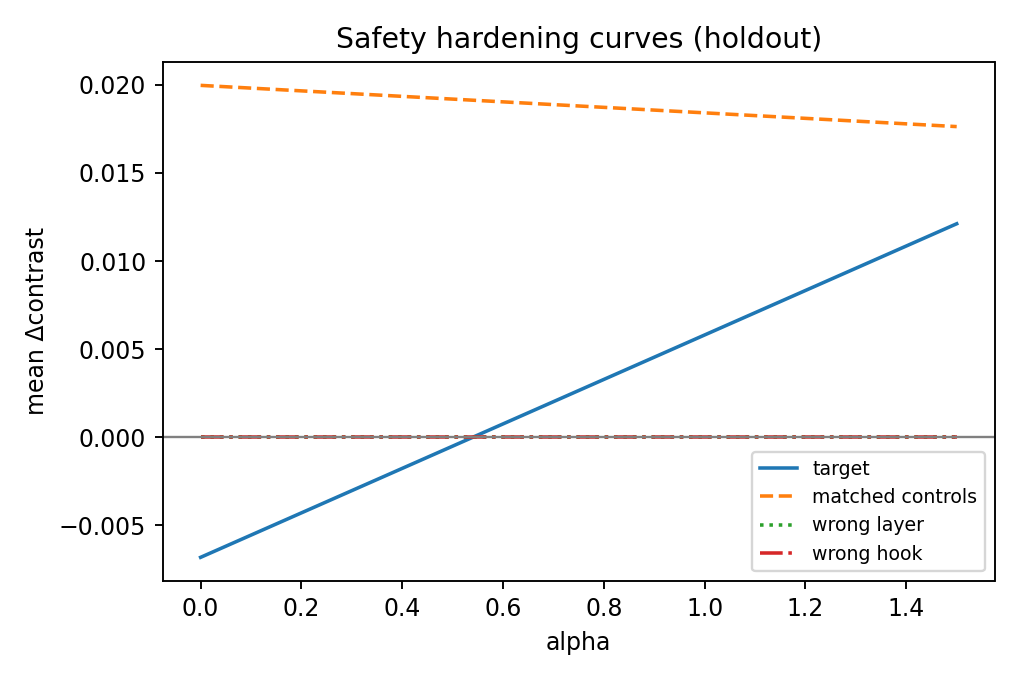
Hardened Results (Holdout, alpha=1.5)
| Category | Target Δcontrast | Controls Δcontrast | Verdict |
|---|---|---|---|
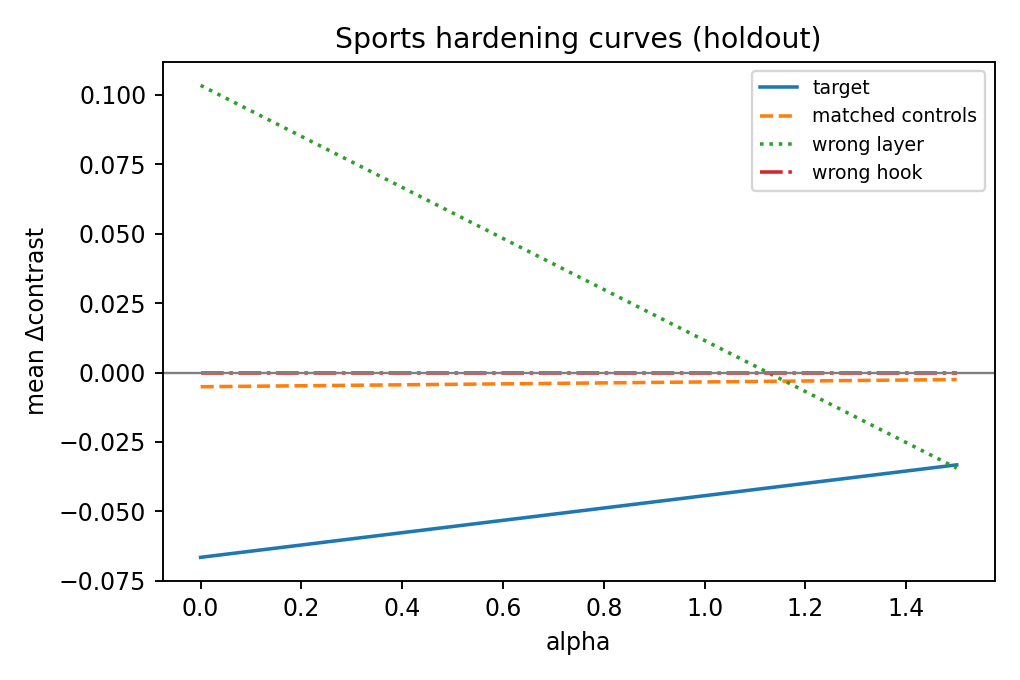
| sports | -0.0332 | -0.0025 | weak / fails transfer-specificity checks |
| code | +0.0288 | -0.0446 | strongest, feature-specific signal |
| safety | +0.0121 | +0.0176 | fails specificity (controls comparable/stronger) |
| uncertainty | +0.0065 | +0.0011 | modest effect, weak specificity |
A practical intuition for the code result: this feature appears to push the model toward programmatic structure (code-like framing) over general procedural prose.
In plain terms, when this feature is amplified, completions more consistently move toward function/API/test/query-style continuations; when suppressed, the same prompts more often remain in generic explanatory prose. This is why I treat the code category as the only currently defensible steering win in this run.
Why code may hold up better here: code has stronger syntactic regularity and sharper token-structure patterns than the other categories, which often makes code-related features easier to separate in SAE space.
Pass/Fail Snapshot (alpha=1.5)
| Category | Target > Controls | Wrong-Layer Weaker | Wrong-Hook Weaker | Holdout Transfer | Quality OK | Seed Stability | Ablation Specific |
|---|---|---|---|---|---|---|---|
| sports | FAIL | FAIL | PASS | FAIL | PASS | FAIL | FAIL |
| code | PASS | PASS | PASS | PASS | PASS | PASS (after extension) | PASS |
| safety | FAIL | PASS | PASS | PASS | PASS | PASS | FAIL |
| uncertainty | PASS | PASS | PASS | PASS | PASS | PASS | FAIL |
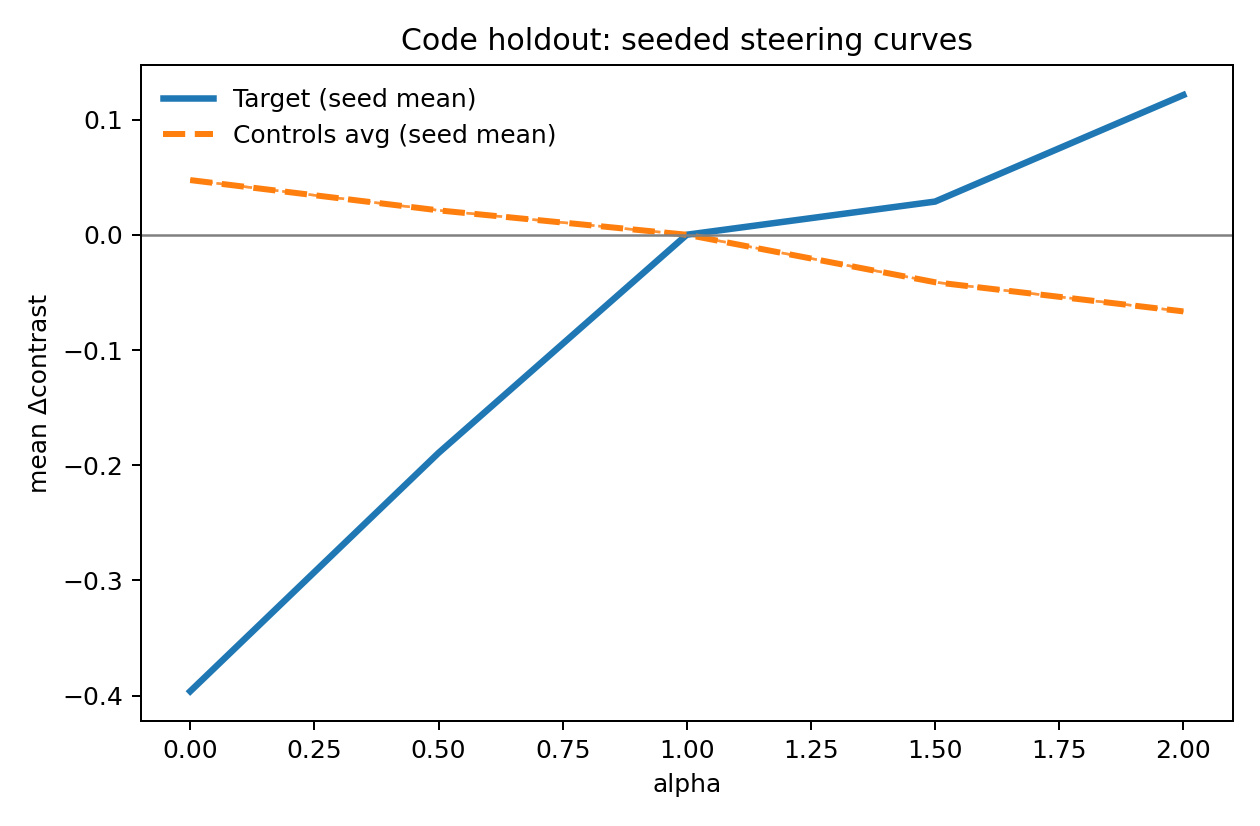
Seed Extension (Code)
I re-ran the code category with expanded seeds (7,17,27,37,47,57,67) and re-evaluated target vs controls + wrong-layer + wrong-hook.
At alpha=1.5:
- target mean:
+0.02877 - controls mean:
-0.04122 - target > controls: PASS
- wrong-layer weaker than target: PASS
- wrong-hook weaker than target: PASS
This keeps the code claim intact under the extended seed pass.
Visuals (What To Look At)
Code (strongest signal)
Seeded code extension
Safety
Sports
Uncertainty
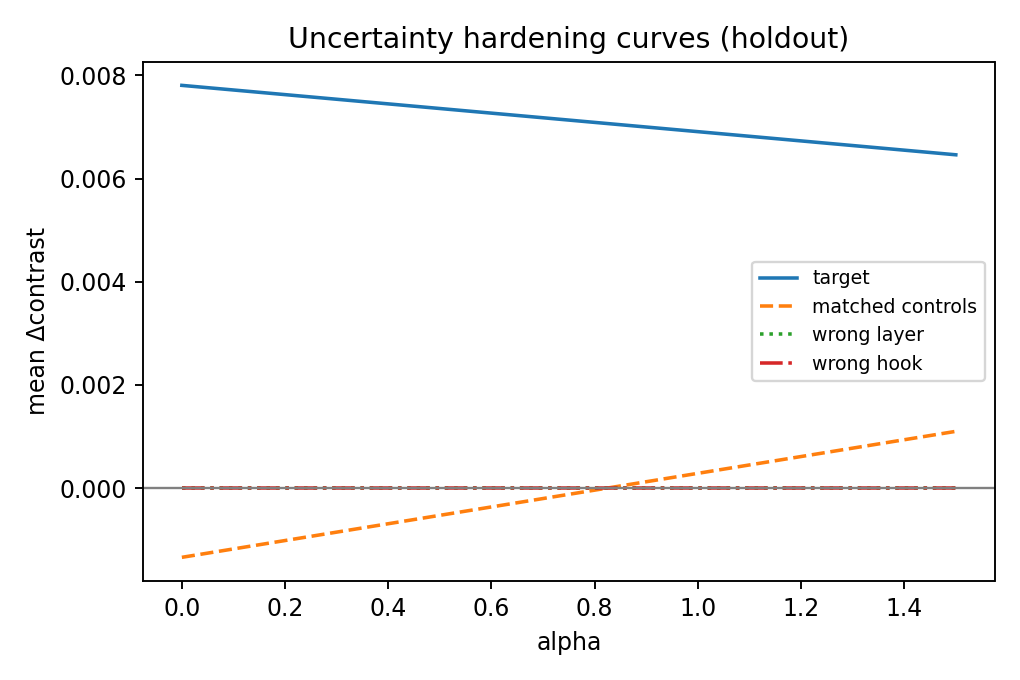
Reading guide:
- If the target line separates from both matched controls and mismatch controls (wrong-layer/wrong-hook) on holdout, that supports feature-specific steering.
- If controls move similarly, treat the effect as likely non-specific perturbation.
Interpretation
The practical conclusion is not “SAE steering is solved.”
It is:
- One category (code) currently survives hardening in this setup.
- Several others do not yet survive the same scrutiny.
- This is exactly why stronger controls are worth the extra effort.
Limitations
- Compact prompt battery (still small relative to broad deployment behavior).
- Holdout templates are better but still synthetic.
- Quality proxies are lightweight, not full human eval.
- A single model family + one SAE release.
What I’d Do Next
- Expand holdout prompt diversity further (especially safety/sports).
- Add stronger semantic control matching for non-code features.
- Add a small blinded human eval panel for quality/retention.
- Replicate the same protocol on another model/SAE family.
References
- Conmy et al. (2024), Gemma Scope: Open Sparse Autoencoders Everywhere All At Once on Gemma 2.
- https://arxiv.org/abs/2408.05147
- Gao et al. (2024), Scaling and Evaluating Sparse Autoencoders.
- https://arxiv.org/abs/2406.04093
- Bricken et al. (2023), Towards Monosemanticity: Decomposing Language Models With Dictionary Learning.
- https://transformer-circuits.pub/2023/monosemantic-features/index.html
- Turner et al. (2023), Steering Language Models With Activation Engineering.
- https://arxiv.org/abs/2308.10248