Research Note
Replicating Natural Language Autoencoder Edits on Gemma 3
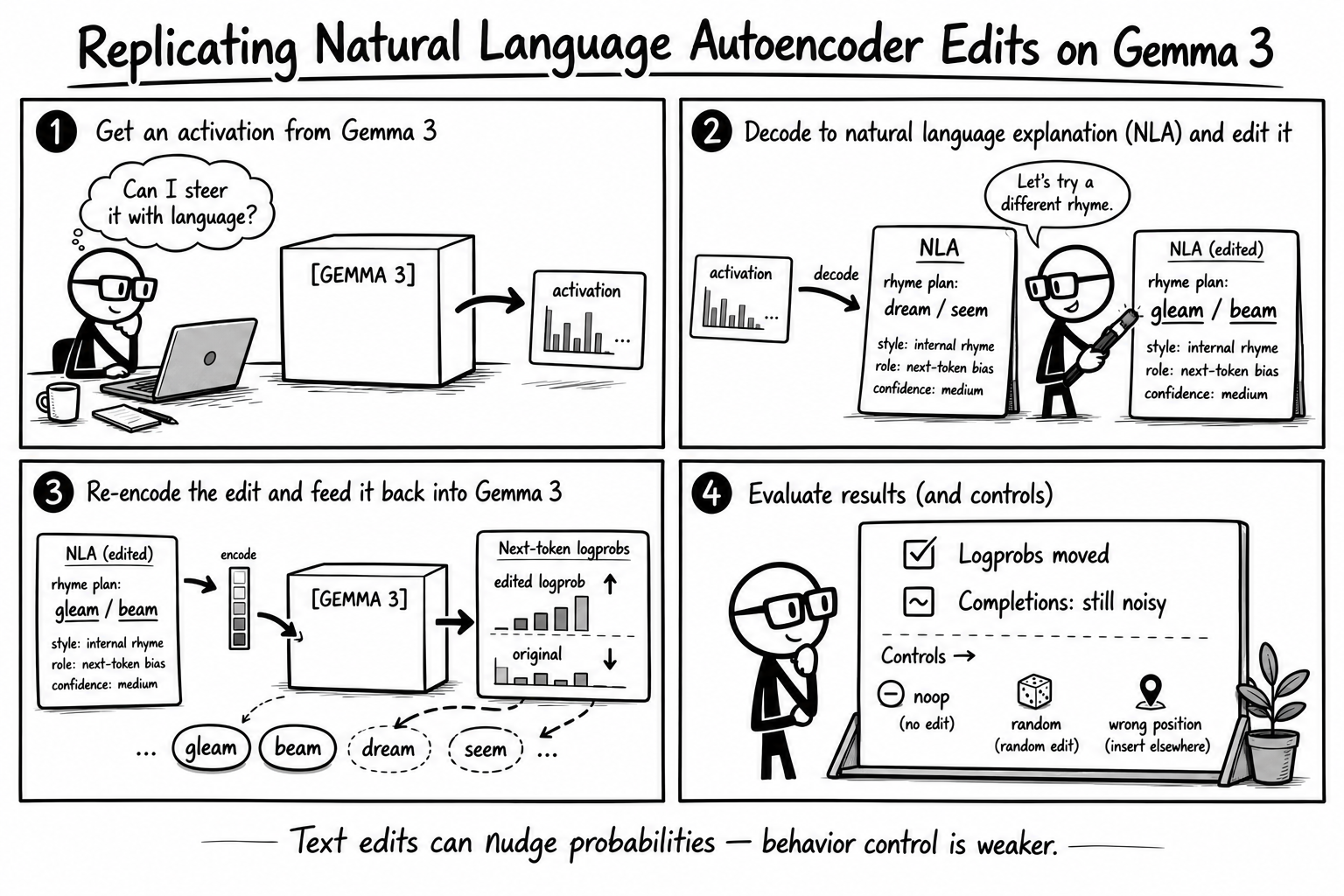
I wanted to answer one practical question:
Can I take the released Natural Language Autoencoder checkpoints, run them locally on Gemma 3 12B activations, and use a text edit to move the model’s next-token distribution in a predictable direction?
Short answer: partially, and with caveats. The text-mediated edit moved next-token logprob mass toward the edited rhyme family on a narrow poetry task. The completion samples moved much less cleanly, and the controls are not clean enough for a strong causal-control claim.
TL;DR (Layman Version)
I tested whether a model explanation written in English could be edited, converted back into an activation, and used to steer Gemma 3’s next word choices. The answer was suggestive but not decisive: the probabilities moved in the intended direction, but sampled completions were noisy.
Why This Post Exists
Most of my interpretability work so far has been SAE-based: find a feature, intervene on that feature, and test whether behavior changes under controls.
This run was inspired by Anthropic’s Transformer Circuits post, Natural Language Autoencoders Produce Unsupervised Explanations of LLM Activations. I wanted to see how much of that explanation/edit loop I could reproduce locally with the released open-weight Gemma checkpoints.
Natural Language Autoencoders offer a different interface. Instead of editing a sparse feature index, the workflow is:
- Extract a residual activation from the model.
- Decode that activation into a natural-language explanation.
- Edit the explanation text.
- Reconstruct an activation from the edited text.
- Inject the activation delta back into the model.
That is the interesting part. If it works, the control surface is not “feature 12345 at layer 20.” It is a sentence.
This post is not a training replication. I used the released Gemma 3 12B NLA checkpoints and replicated a small inference-side edit probe.
What Changed And Why
The first pass was too demo-like. I could generate explanations and reconstruct activations, but the poetry edit was broad and the sampled completions mostly stayed on the original rhyme.
The second pass narrowed the edit. Instead of changing stream/dream into an unrelated rhyme family, I tested a same-rhyme edit like dream -> gleam. That produced a clearer next-token logprob shift, but it was still only one prompt.
The third pass added the minimum controls I would want before writing anything:
- 8 short couplet prompts instead of 1.
target_edit,noop,unrelated_edit,random_delta, andwrong_positionconditions.- Logprob mass as the primary metric.
- Sampled completions as a secondary sanity check only.
That made the result less pretty but more useful.
Setup
- Base model:
google/gemma-3-12b-it - AV checkpoint:
kitft/nla-gemma3-12b-L32-av - AR checkpoint:
kitft/nla-gemma3-12b-L32-ar - Layer/stream: layer 32 residual activation
- Device: local Mac / MPS path
- Dtype:
bfloat16 - Prompt count: 8 couplet prompts
- Explanations: 2 AV samples per prompt in the final local run
- Alpha sweep:
[-2, -1, 0, 1, 2, 4, 8] - Completion sampling: one seed, alpha
0and2, short qualitative samples - Primary metric: edited rhyme-family next-token logprob mass minus original rhyme-family next-token logprob mass
The exact command for the V3 run was:
python -m src.nla_gemma3_probe --config configs/nla_gemma3_poetry_v3.yaml --step all
The local run used a recompute-first pipeline: load Gemma to extract compact activation vectors, unload it, load the AV model to generate explanations, unload it, load the AR model to reconstruct edited activations, unload it, then reload Gemma for logprob and completion probes.
That matters on this machine because keeping the base model, AV, and AR resident together is the wrong memory tradeoff.
Evaluation Protocol
For each prompt, I extracted the layer-32 residual activation at the target token. The target position was the line break / end of the first line, where a continuation or rhyme plan should matter.
Then I generated AV explanations from the saved activation and scored them with AR reconstruction quality. If an explanation mentioned an editable candidate term, I selected the best reconstruction among those. Otherwise I used the best reconstruction fallback.
For the edit condition, I replaced lexical planning terms in the explanation, reconstructed the edited activation, and injected:
delta = AR(edited explanation) - AR(original explanation)
The controls were:
noop: zero delta.unrelated_edit: edit the explanation toward an unrelated word family.random_delta: normalized random direction.wrong_position: target edit delta injected at the neighboring token position.
The main measurement is next-token logprob mass on two term families:
- original terms, such as
dream,seem - edited terms, such as
gleam,beam
Higher edited - original means the model’s next-token distribution moved toward the edited rhyme family.
Core Results
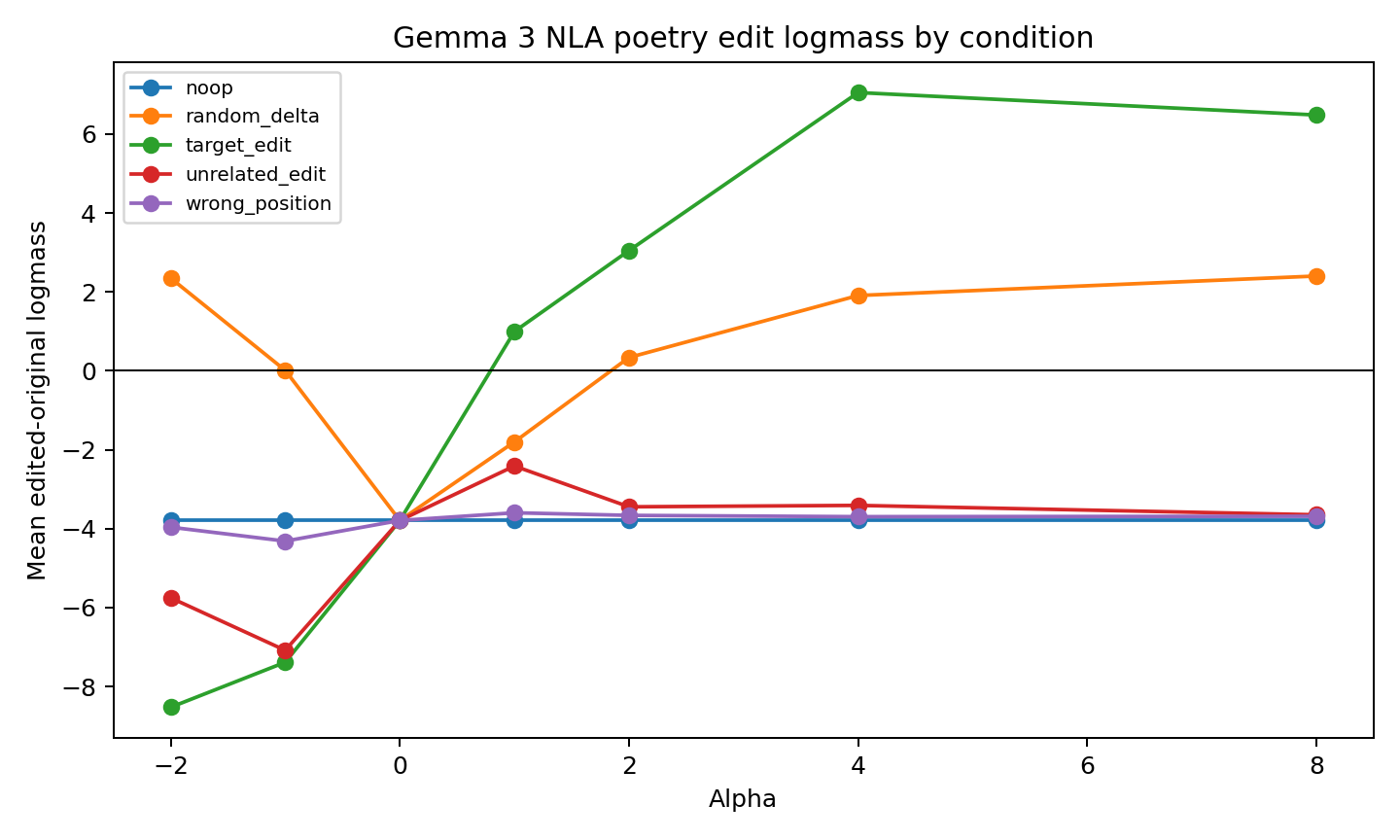
The target edit moved in the intended direction at positive alphas. The strongest aggregate point was:
- Target edit at alpha 4: mean edited-minus-original logmass
+7.050 - Prompts positive:
4/8 - Median:
+0.044
That is the honest headline. The mean moved strongly, but the median barely crossed zero because the effect is concentrated in a few prompts.
| condition | alpha | mean edited-original logmass | median | positive prompts |
|---|---|---|---|---|
target_edit |
2 | +3.045 | -0.288 | 3/8 |
noop |
2 | -3.793 | -4.510 | 1/8 |
unrelated_edit |
2 | -3.447 | -0.564 | 3/8 |
random_delta |
2 | +0.337 | +1.934 | 5/8 |
wrong_position |
2 | -3.664 | -4.190 | 1/8 |
target_edit |
4 | +7.050 | +0.044 | 4/8 |
noop |
4 | -3.793 | -4.510 | 1/8 |
unrelated_edit |
4 | -3.411 | -0.965 | 2/8 |
random_delta |
4 | +1.908 | +1.724 | 5/8 |
wrong_position |
4 | -3.697 | -4.286 | 1/8 |
target_edit |
8 | +6.482 | +0.499 | 4/8 |
noop |
8 | -3.793 | -4.510 | 1/8 |
unrelated_edit |
8 | -3.649 | -2.076 | 2/8 |
random_delta |
8 | +2.401 | +1.530 | 4/8 |
wrong_position |
8 | -3.687 | -4.295 | 1/8 |
The most useful read is not “NLA steering worked.” It is narrower:
The targeted text edit produced a larger positive logprob shift than no-op, unrelated edit, and wrong-position controls at alpha 4 and 8, but random directions also moved probability mass in some cases.
That prevents a clean causal claim.
Per-Prompt Heterogeneity
The alpha-4 result was not evenly distributed.
| prompt | target edit alpha 4 edited-original logmass |
|---|---|
bird_word |
+37.612 |
fire_desire |
-4.064 |
hill_still |
-1.067 |
night_light |
+0.149 |
rain_pane |
+19.949 |
shore_more |
+10.212 |
snow_glow |
-0.061 |
stream_dream |
-6.328 |
Three prompts drove most of the mean: bird_word, rain_pane, and shore_more.
That is both encouraging and limiting. It means the pipeline can produce large targeted shifts, but it also means the current prompt/explanation selection rule is not reliable enough to treat as general.
Half the prompts used fallback explanations where the selected AV text did not mention an editable candidate term. Those cases are weaker evidence for text-mediated control because the actual edit may not touch the part of the explanation carrying the relevant plan.
Completion Samples
The completion samples were weaker than the logprob results.
| condition | alpha | n | original hit rate | edited hit rate |
|---|---|---|---|---|
noop |
0 | 8 | 0.500 | 0.125 |
noop |
2 | 8 | 0.500 | 0.125 |
random_delta |
0 | 8 | 0.500 | 0.125 |
random_delta |
2 | 8 | 0.750 | 0.125 |
target_edit |
0 | 8 | 0.500 | 0.125 |
target_edit |
2 | 8 | 0.625 | 0.250 |
The target edit doubled edited-term hit rate from 0.125 to 0.250, but that is one seed and eight prompts. I would not hang a behavioral claim on it.
The qualitative samples also had typical local-generation messiness: answer-option formatting, partial quiz-like continuations, and occasional off-task fragments. That is why I treat completions as a sanity check, not the main result.
Interpretation
The best evidence is that the released NLA checkpoints can support a local text-to-activation edit loop on Gemma 3 12B:
- AV explanations were coherent enough to inspect.
- AR reconstruction cosine scores were high, roughly around
0.99for selected explanations. - Edited AR deltas changed next-token probability mass in the intended direction on a subset of prompts.
- Wrong-position and unrelated-edit controls were mostly weaker than the targeted edit.
The weakest evidence is behavioral control. The model’s sampled completions did not consistently switch to the edited rhyme family. That is not surprising: next-token logprob movement is a lower-level metric than visible completion behavior, especially under sampling and short prompts.
My current interpretation is:
NLA edits are a promising text-mediated activation editing interface, but this run supports a probability-shift claim more than a behavior-control claim.
Why This Is Different From The SAE Work
With the Gemma SAE steering experiments, the interface was feature-index-first. I selected features, scaled them, and checked whether behavior moved under controls.
Here the interface is explanation-first. The editable object is not a sparse feature. It is a natural-language hypothesis about what the activation represents.
That changes the debugging loop. With SAEs, the hard part is choosing and validating the feature. With NLA, the hard part is making sure the explanation text actually captures the causal content you want to edit. The fallback explanations in this run show that problem clearly.
What I Would Test Next
The evidence could improve with a few obvious changes:
- Generate more AV explanations per prompt and select only explanations with editable planning terms.
- Add more generation seeds for completion behavior.
- Expand the prompt battery beyond same-rhyme lexical substitutions.
- Add bootstrap confidence intervals for the logprob effect.
- Re-run with a stronger selection rule that drops fallback prompts instead of editing them.
If those changes preserve the target-vs-control separation, the claim gets stronger. If they do not, the honest conclusion stays narrow: local NLA explanation/edit construction works, but the causal probe is weak.
Limitations
- This is an inference-side replication using released checkpoints, not NLA training.
- The model path is local Transformers/MPS, not Anthropic’s internal setup or the upstream serving stack.
- The task is narrow: short poetry/rhyme prompts, one target layer, and lexical same-rhyme edits.
- The prompt count is small at
n=8. - Completion sampling used one seed in the V3 run, so behavior-level claims are intentionally weak.
- Random deltas sometimes moved edited-term logprob too, which limits causal specificity.
- Some selected explanations did not contain editable candidate terms, making those prompt-level edits less meaningful.
- String-hit completion scoring is a crude proxy.
Next Steps
The next run should be stricter, not bigger for its own sake.
I would first filter to prompts where the AV explanation explicitly names an editable plan or rhyme term. Then I would run more explanation samples and more completion seeds on that smaller, cleaner set.
The decision rule should be simple: if target edits beat no-op, unrelated, random, and wrong-position controls on both logprob and completion samples, the post can make a stronger causal claim. If not, the post should stay framed as an inference-side replication with a weak causal probe.
References
- Fraser-Taliente, Kantamneni, Ong, et al. (2026), Natural Language Autoencoders Produce Unsupervised Explanations of LLM Activations, Transformer Circuits.
TL;DR
I reproduced the local Gemma 3 NLA explanation/edit loop and got suggestive next-token probability shifts, but the current evidence supports only a cautious claim: text-mediated activation editing moved logprobs more than it reliably steered completions.